Joint Open Genome and Omics Platform (JoGo) is a project that constructs and catalogs high-resolution haplotype databases, mainly based on 3rd-generation long-read sequencing technologies. The version 1 dataset release (JoGo 1.0) consists of 258 global datasets, including 130 East Asia (EAS), 50 African (AFR), 44 American (AMR), 25 South Asia (SAS), 9 European (EUR). Among them, 108 datasets were originally sequenced by using 3rd-generation high-fidelity (HiFi) long-read sequencer.
These sample sources are from the HapMap project, which contains genotype information of whole-genome regions that are already known by SNP Array genotyping technology and 2nd generation short-read sequencing technology. These datasets are shared in public to derive the open science community.
Human chromosomes inherit one chromosome from the father and the other from the mother. Thus, the 3rd-generation sequencing data from one individual are a mixture of two chromosomes. To reconstruct the haplotype, each sequencing read should be separated into two haplotype groups and rebuild the original chromosome.
Five key milestones were established for the JoGo 1.0 release:
1. Construct and catalog haplotypes for coding genes, as defined by the MANE database. 2. Assign consistent haplotype IDs to the cataloged haplotypes from step 1. 3. Catalog single nucleotide polymorphisms (SNPs), short insertions and deletions (under 50 bases), and long insertions and deletions (over 50 bases). 4. Annotate the variants cataloged in step 3 by comparison with the T2T primates dataset. 5. Provide access to all haplotype catalogs for download or exploration using the de facto standard genome viewer, Integrative Genomics Viewer (IGV).
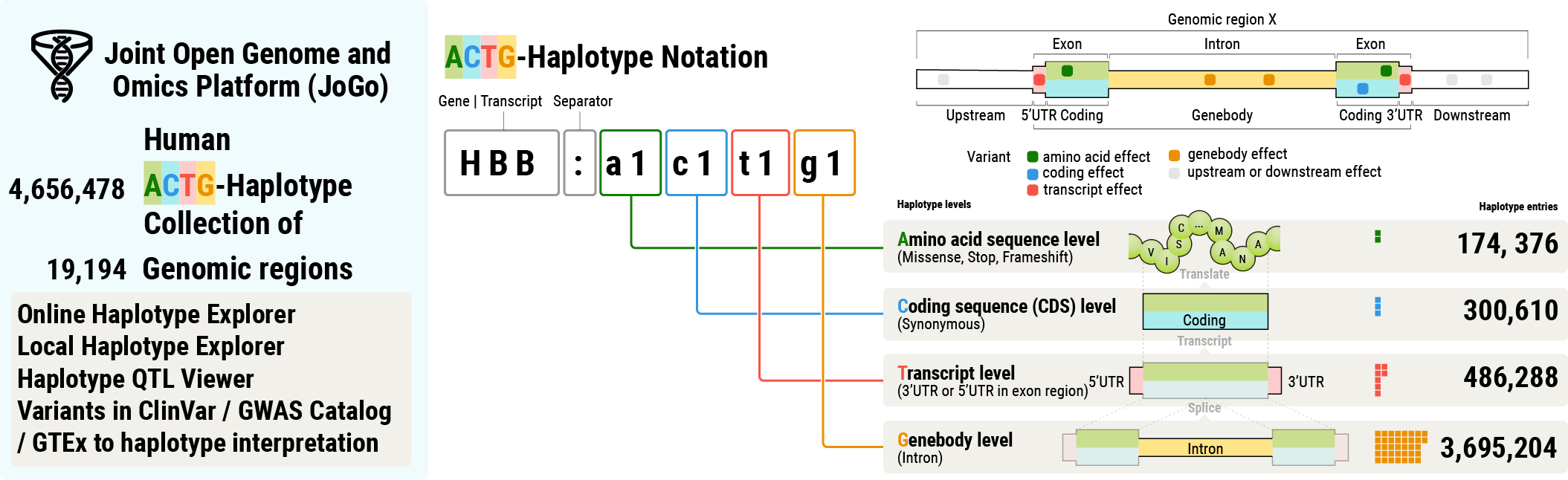
JoGo1.0 is based on the Matched Annotation from the NCBI and EMBL-EBI (MANE) release 1.2 (21st/Jul/2023) for human protein-coding genes and constructed the coding gene haplotype catalog of 19,194 genes with 174,376 / 300,610 / 486,288 / 3,695,204 haplotypes (Amino acids/Coding/Transcript/Genebody level: ATCG haplotype nomenclature).
Using the coding region annotation of MANE in GRCh38, all cataloged genic haplotypes in JoGo1.0 are annotated by the amino acids (174,376) / coding (300,610) / transcript (486,288) / genebody (3,695,204) level ids and numbered by high-frequency type in JoGo v1 database, e.g., a1 (60%), a2 (30%), a3 (10%).
Among 4,651,897 haplotypes from 19,194 genomic regions, the JoGo1.0 cataloged 13,613,642 SNV, 1,669,786 and 1,364,238 short insertions and deletions, and 332,421 and 69,409 long insertions and deletions with 3rd generation long-read sequencing technology.
Cataloged variants in JoGo1.0 are annotated by the latest T2T primates dataset (Gorilla, Chimpanzee, Orangutan, Bonobo; Telomere-to-Telomere consortium primates project). The annotation allows us to interpret the source of variants and haplotype level inheritance to humans from primates.
For future interpretation by each researcher, all haplotype datasets can be explored interactively on online haplotype explorer or local haploytpe explorer with a genome viewer (iGV) on each user's desktop machine. By saving the session XML file of iGV on a local machine, users can share the custom view with collaborators (since the original haplotype dataset is on the JoGo website and can load the collaborator without sending the raw dataset. The XML session file points to the URI in JoGo website).
We plan to provide a minor update after the release of JoGo1.0. The version numbering of minor updates will be JoGo1.x, i.e., 1.1, 1.2. The next major release (2.0) will increase the size of samples (to catalog haplotypes) and include the annotation by Omics dataset part of JoGo1.x samples.
If you have any questions or requests, please contact us.
ACTG-Haplotype Collection
Sample Distribution by Population
Demo target: HBB_chr11_5220464_5232071 (GRCh38 coordinates)